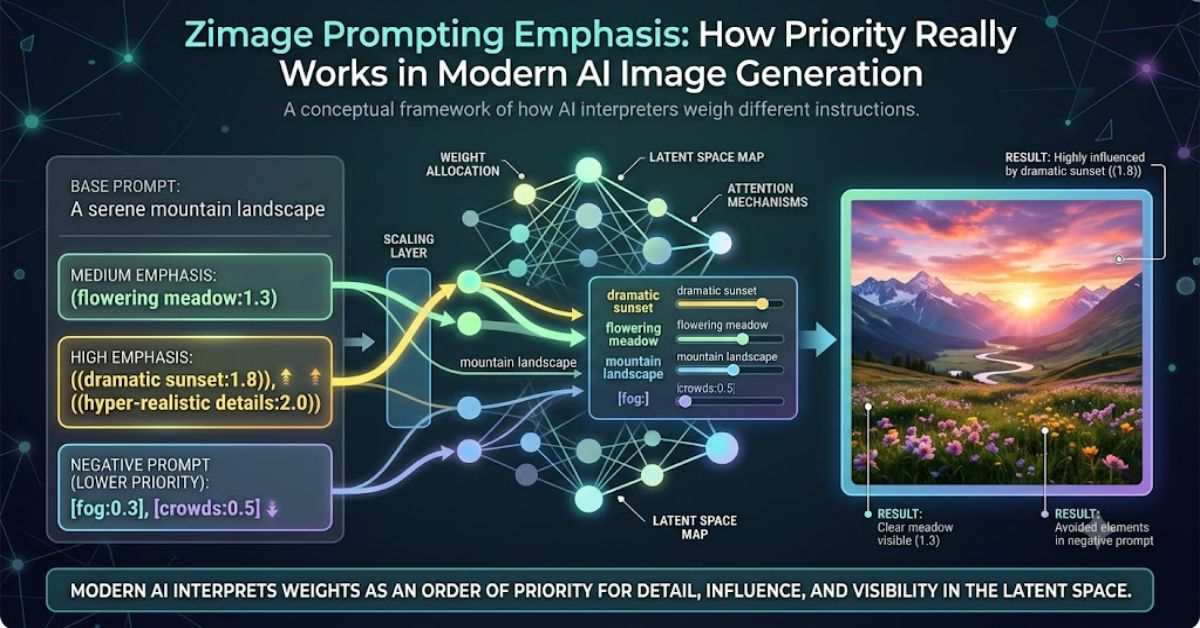
Anyone searching for zimage prompting emphasis is usually trying to answer a simple question: how do you tell Z-Image what matters most in a prompt?
The short answer is that Z-Image works differently from many older image generation systems. Traditional Stable Diffusion workflows often relied on syntax such as (masterpiece:1.4) or repeated keywords to increase emphasis. Z-Image, particularly newer variants that use large language model (LLM) text encoders, places far greater importance on context, sentence structure, and semantic relationships between concepts.
This shift changes how prompts should be written. Instead of treating prompts like lists of weighted tags, users achieve better results by describing scenes naturally and placing important concepts early in the prompt. The model interprets language more like a reader than a keyword parser.
Understanding this distinction can dramatically improve image quality. Many users struggle because they apply prompting habits learned from older diffusion models. As a result, prompts become cluttered with excessive weighting syntax, redundant descriptors, and repeated phrases that add noise rather than clarity.
This guide explains how modern emphasis works inside Z-Image, where traditional techniques still help, when they fail, and how creators can write prompts that align with the strengths of contemporary AI image generation systems.
What Is Prompt Emphasis?
Prompt emphasis refers to the methods used to communicate priority within an image generation request.
When a user enters a prompt, the system must decide:
- Which subject is most important
- Which visual elements deserve attention
- Which stylistic attributes should dominate
- Which details are secondary
In older image generators, emphasis often depended on mathematical weighting.
For example:
| Method | Purpose | Common Usage |
| Parentheses | Increase importance | (portrait) |
| Numerical weights | Strong emphasis | (portrait:1.5) |
| Repetition | Reinforcement | portrait portrait portrait |
| Negative prompts | Reduce unwanted features | blurry, low quality |
Modern Z-Image models frequently rely less on these techniques and more on language comprehension.
Why Z-Image Uses a Different Approach
The most important factor behind zimage prompting emphasis is the adoption of LLM-based text encoding.
Older systems treated prompts almost like collections of labels.
Example:
portrait, woman, blue eyes, cinematic lighting, realistic
Modern systems process richer linguistic relationships.
Example:
A cinematic portrait of a woman with striking blue eyes standing beneath soft evening light, photographed with a shallow depth of field.
The second prompt provides context, hierarchy, and meaning.
The model can determine:
- Primary subject
- Supporting attributes
- Scene relationships
- Visual priorities
As a result, descriptive language becomes a form of emphasis.
How Z-Image Decides What Matters Most
1. Prompt Position
Information appearing earlier often receives greater attention.
Consider:
Prompt A
“A majestic dragon flying over a medieval city at sunset.”
Prompt B
“A medieval city at sunset with a majestic dragon flying overhead.”
Both describe the same scene.
However, Prompt A tends to prioritise the dragon while Prompt B may allocate more visual attention to the city.
Prompt ordering acts as a natural weighting mechanism.
2. Contextual Importance
The model analyses relationships between concepts.
Example:
“A close-up portrait of a violinist performing on stage.”
The violinist becomes the focal point because the entire sentence revolves around that subject.
The stage exists as supporting context.
This behaviour mirrors how humans interpret language.
3. Descriptive Density
More detail often signals importance.
Compare:
“An astronaut.”
versus
“A weathered astronaut wearing a reflective helmet, standing alone on a crimson Martian ridge beneath a dusty orange sky.”
The latter naturally receives more emphasis because additional descriptive information creates stronger semantic focus.
Traditional Weighting vs Modern Language-Driven Prompting
Many creators transition from Stable Diffusion ecosystems and bring older habits with them.
The comparison below highlights the difference.
| Approach | Older Diffusion Models | Z-Image Models |
| Keyword repetition | Highly influential | Limited benefit |
| Parenthesis weighting | Important | Often less significant |
| Natural language | Secondary | Primary |
| Semantic relationships | Limited | Strong |
| Long descriptive prompts | Mixed results | Frequently beneficial |
| Narrative structure | Low importance | High importance |
This explains why many users report better outputs after simplifying prompts rather than making them more complex.
Practical Techniques for Better Z-Image Prompting
Lead With Your Subject
The primary subject should appear first.
Instead of:
“A rainy city street with a photographer taking pictures.”
Try:
“A professional photographer capturing images on a rainy city street.”
The emphasis shifts immediately.
Describe Before Styling
Users often overload prompts with artistic descriptors.
Less effective:
“Masterpiece, ultra detailed, cinematic, award winning, realistic portrait.”
More effective:
“A realistic portrait of an elderly sailor with weathered skin and thoughtful eyes, photographed in cinematic evening light.”
The subject gains clarity before style modifiers are introduced.
Use Complete Thoughts
Fragments can work, but complete descriptions frequently produce more coherent images.
Example:
“A luxury watch resting on black marble under dramatic studio lighting.”
The model understands relationships between all objects in the scene.
Common Mistakes That Reduce Emphasis
Excessive Keyword Stuffing
Many users attempt to increase importance through repetition.
Example:
“Dragon dragon dragon dragon dragon.”
Modern models often gain little benefit from this approach.
Instead, repetition can introduce noise and unpredictability.
Competing Subjects
Consider:
“A dragon, a castle, a knight, a wizard, a giant eagle, a battlefield.”
The model receives multiple high-priority concepts simultaneously.
Visual focus becomes diluted.
A better strategy is defining a clear hierarchy.
Overuse of Weights
Some users import heavily weighted prompts from older workflows.
Example:
((dragon)), (((castle))), (epic:1.5), (masterpiece:1.4)
While some systems still interpret weighting, excessive syntax may contribute less than clear language.
Real-World Testing Observations
Several public prompt engineering communities have documented similar patterns since the rise of LLM-enhanced image models in 2024 and 2025.
Observed trends include:
| Prompt Strategy | Typical Outcome |
| Natural descriptions | Higher coherence |
| Weighted keyword spam | Inconsistent improvements |
| Clear subject-first prompts | Strong focal points |
| Narrative scene descriptions | Better composition |
| Excessive tags | Reduced clarity |
One recurring finding among experienced users is that rewriting a prompt often improves output more than increasing weights.
That reflects a fundamental shift from token emphasis toward semantic emphasis.
Strategic Implications for Creators
Understanding zimage prompting emphasis has practical value beyond hobbyist image generation.
Professional users increasingly rely on AI for:
- Marketing campaigns
- Product visualisation
- Storyboarding
- Concept art
- Editorial illustration
These workflows benefit from predictability.
Teams that adopt natural-language prompting typically spend less time iterating and correcting outputs.
A concise, descriptive prompt often produces more reliable results than a heavily weighted prompt assembled from dozens of tags.
Hidden Limitations Few Guides Mention
Ambiguity Still Wins Sometimes
Even advanced language models occasionally misinterpret priority.
Long prompts containing multiple subjects may create competing attention signals.
Prompt Length Has Diminishing Returns
Adding detail helps only until meaningful information becomes repetitive.
After a certain threshold, additional words contribute little value.
Style Can Override Subject
Strong style instructions occasionally dominate scene instructions.
For example:
“Abstract cubist painting”
may influence output more heavily than detailed object descriptions.
Understanding this interaction remains important when balancing content and aesthetics.
The Future of Zimage Prompting Emphasis in 2027
Several trends suggest where prompting is heading.
First, multimodal reasoning systems continue improving semantic understanding. Future models will likely infer emphasis from context, intent, and conversation history rather than explicit weighting syntax.
Second, conversational prompting is becoming more common. Users increasingly refine images through dialogue rather than rewriting prompts from scratch.
Third, image generation systems are moving toward instruction-following architectures similar to modern LLMs.
This evolution suggests that natural language proficiency may become more valuable than specialised prompt syntax.
However, traditional weighting mechanisms may not disappear entirely. They remain useful for edge cases where precise control is required.
The most likely outcome is a hybrid approach that combines language understanding with optional weighting controls for advanced users.
Key Takeaways
- Prompt order strongly influences visual priority.
- Natural language generally outperforms keyword stuffing.
- Semantic context often matters more than token weighting.
- Subject-first prompts create clearer compositions.
- Excessive emphasis syntax can reduce clarity.
- Narrative descriptions help establish hierarchy.
- Future models are likely to rely even more on language understanding.
Conclusion
The biggest lesson from studying zimage prompting emphasis is that modern image generation systems reward communication rather than manipulation.
Many prompting techniques inherited from early diffusion workflows still have niche applications, but they no longer represent the primary mechanism for controlling output. Instead, Z-Image models increasingly rely on semantic interpretation, contextual understanding, and language structure.
Users who focus on clarity usually achieve better results than those who focus on weighting syntax. A well-written sentence describing a scene often provides stronger guidance than a prompt packed with repeated keywords and emphasis markers.
As AI image generators continue adopting more advanced language architectures, prompting is becoming less about discovering hidden tricks and more about expressing visual ideas clearly. That shift makes image generation more accessible while also rewarding creators who understand how language shapes machine interpretation.
FAQ
What is zimage prompting emphasis?
It refers to the techniques used to signal importance within a Z-Image prompt. Modern Z-Image models primarily use language structure and semantic understanding rather than heavy keyword weighting.
Does Z-Image support prompt weights?
Some implementations may recognise weighting syntax, but the effect is often less significant than it was in earlier Stable Diffusion workflows.
Is keyword repetition useful?
Usually not. Repetition can introduce noise and rarely provides the dramatic emphasis boost users expect.
Why does prompt order matter?
Concepts introduced earlier frequently receive greater attention because the model interprets them as central subjects.
Should I use natural sentences or keyword lists?
Natural descriptions generally produce stronger and more coherent results in LLM-enhanced image generation systems.
Can style instructions override subjects?
Yes. Strong stylistic directives can occasionally dominate visual priorities, especially when the prompt lacks a clearly defined main subject.
Are parentheses still important?
They can help in certain implementations, but natural language and contextual clarity often provide greater influence over the final image.
Methodology
This analysis was produced through a review of publicly available documentation, AI image generation research, prompt engineering discussions, and observed behaviour across contemporary image-generation systems that utilise LLM-enhanced text encoders.
The article compares traditional Stable Diffusion prompting practices with newer semantic prompting approaches. No proprietary testing data was used. Behaviour may vary between model versions and implementations.
Counterarguments exist. Some image-generation systems continue to respond strongly to weighting syntax, particularly models built on earlier diffusion architectures. Readers should test prompting methods within their specific workflow.
Editorial Disclosure: This article was drafted with AI assistance and reviewed and verified by the editorial team at RubbleMagazine.co.uk. All claims, examples, and references should be independently reviewed before publication.





