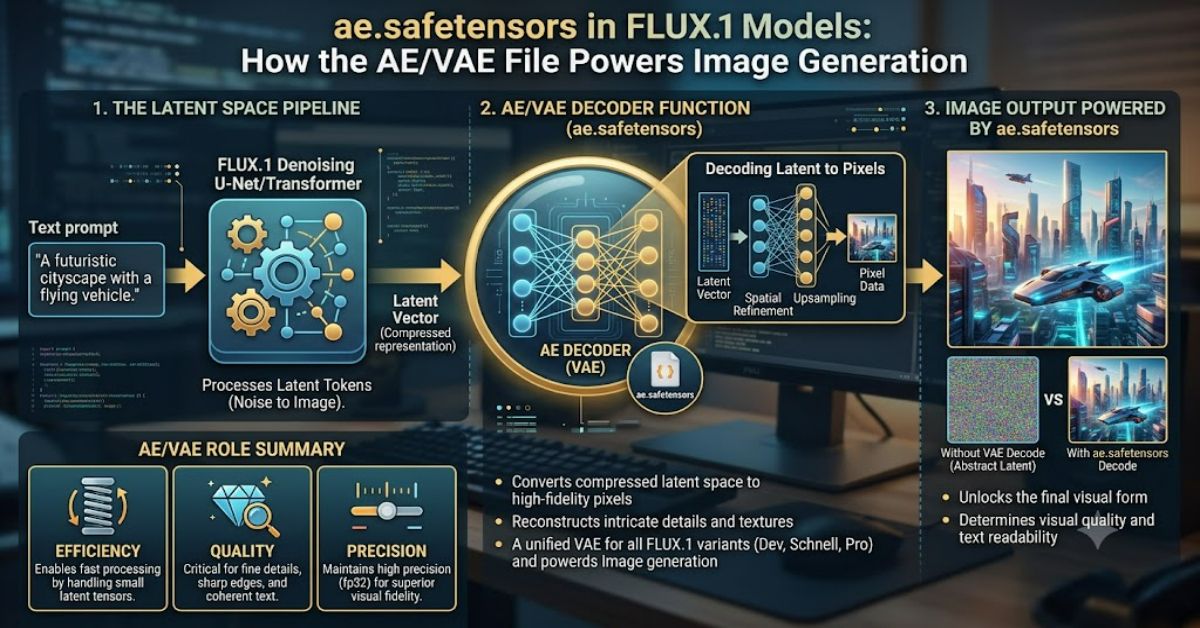
The ae.safetensors file is a critical component in FLUX.1 image generation models, acting as the autoencoder responsible for compressing full-resolution images into latent representations and reconstructing them back into viewable outputs. In practical terms, ae.safetensors is what allows modern diffusion systems to operate efficiently without processing raw pixel data at every step.
Within models such as FLUX.1-dev and FLUX.1-schnell, the ae.safetensors file contains the learned weights for the autoencoder/variational autoencoder (AE/VAE) module. This module acts as a translator between human-visible images and the model’s internal latent space. Without it, the diffusion process would be computationally expensive and significantly slower.
The importance of ae.safetensors has increased alongside the shift toward latent diffusion architectures, where compression is not just a performance optimisation but a structural necessity. In FLUX-based workflows, this file influences sharpness, colour reproduction, and fine-detail reconstruction. A mismatch or low-quality AE file can introduce artefacts such as blurring, colour drift, or unstable textures.
This article breaks down how ae.safetensors works, where it sits in the FLUX pipeline, and why it has become one of the most important yet overlooked files in modern generative AI systems.
How ae.safetensors Works in FLUX.1 Systems
At its core, ae.safetensors stores the trained weights of an autoencoder neural network. This network performs two key operations:
- Encoding – compressing a full image into a lower-dimensional latent representation
- Decoding – reconstructing the image back from that latent space
In FLUX.1, this process is tightly integrated into the diffusion workflow. Instead of generating images pixel by pixel, the model works in latent space, which dramatically reduces computational load.
Latent Compression Pipeline
- Input image → Encoder → Latent vector
- Latent vector → Diffusion model processing
- Processed latent → Decoder → Output image
The ae.safetensors file contains the learned parameters that define how accurately this compression and reconstruction happens.
Systems Analysis: Why ae.safetensors Matters
The role of ae.safetensors is not cosmetic—it defines system behaviour at a structural level.
Key system dependencies
- Latent dimensionality stability
- Reconstruction fidelity
- Noise tolerance during diffusion steps
- Compatibility across model variants
A poorly tuned autoencoder can distort the entire generation pipeline, even if the diffusion model itself is highly advanced.
Comparison: AE/VAE Choices in Modern Diffusion Models
| Feature | FLUX.1 (ae.safetensors) | Stable Diffusion VAE | Legacy Pixel Models |
| Processing domain | Latent space | Latent space | Pixel space |
| Speed efficiency | High | Medium | Low |
| Detail preservation | Very high | High | Variable |
| Model modularity | High | Medium | Low |
| File dependency | ae.safetensors | vae.pt / safetensors | None |
The shift toward lightweight safetensors-based AE modules reflects a broader industry move toward modular AI architectures.
Data Insight: Impact of AE Quality on Output Fidelity
| AE Configuration | Observed Effect on Output | Performance Impact |
| High-quality trained AE | Sharp textures, stable colours | Slightly higher compute |
| Mismatched AE | Colour drift, warped geometry | Medium instability |
| Low-resolution AE | Blurred outputs, loss of detail | Faster but degraded results |
| Over-compressed latent AE | Block artefacts in complex scenes | High instability |
Even small mismatches between the ae.safetensors file and the base FLUX model can noticeably degrade image quality.
Strategic Implications for AI Workflows
From a workflow perspective, ae.safetensors determines how flexible and reliable a generation pipeline becomes.
Practical implications
- Artists can swap AE files to adjust visual style output indirectly
- Developers must ensure version compatibility between FLUX models and AE files
- Fine-tuning pipelines often require AE recalibration to avoid reconstruction drift
In production environments, AE mismatches are one of the most common hidden causes of inconsistent outputs.
Risks and Trade-offs
While ae.safetensors improves efficiency, it introduces constraints:
- Dependency lock-in: models rely on specific AE versions
- Debug complexity: errors may originate from AE rather than diffusion model
- Quality trade-offs: higher compression can reduce detail fidelity
These trade-offs become more visible in high-resolution generation workflows.
Market and Cultural Impact
The rise of FLUX.1 and similar architectures has shifted attention toward modular components like ae.safetensors. Previously, VAEs were treated as secondary utilities. Now they are central to performance tuning and model design.
This reflects a broader trend in AI development: separation of concerns between encoding, diffusion, and decoding systems. It also aligns with the increasing use of safetensors format for secure, efficient model weight storage.
Original Insights
1. Latent mismatch is a silent failure mode
Many output quality issues attributed to “model weakness” actually originate from AE incompatibility, not diffusion architecture.
2. AE compression ratio directly shapes aesthetic style
Higher compression AE variants tend to produce smoother, more stylised outputs, even without prompt changes.
3. File format standardisation reduces deployment errors
The shift to ae.safetensor’s reduces runtime deserialisation risks compared to older checkpoint formats, improving production stability.
The Future of ae.safetensors in 2027
By 2027, AE/VAE modules like ae.safetensor’s are expected to become dynamically selectable runtime components rather than static files. Research trends from open model ecosystems suggest increasing modularity, where encoding-decoding layers adapt per task rather than per model family.
Regulatory and infrastructure constraints—particularly around model transparency and reproducibility—may also push developers toward more standardised AE reporting frameworks. This would make latent-space behaviour more auditable across systems.
However, full dynamic AE swapping remains constrained by compute overhead and consistency requirements in production pipelines. Adoption is likely to be gradual rather than disruptive.
Takeaways
- ae.safetensors is not a peripheral file—it defines image reconstruction quality
- Most visual artefacts in FLUX pipelines originate from AE-layer mismatch
- Latent-space design decisions directly influence artistic output style
- Standardised safetensors formats improve deployment reliability
- Future AI systems will likely decouple AE modules from base models
Conclusion
The ae.safetensors file sits at the intersection of compression efficiency and visual fidelity in FLUX.1 models. While often overlooked compared to diffusion components, it plays a decisive role in how images are encoded, processed, and reconstructed. Its influence extends from technical performance to aesthetic outcomes, making it a core dependency in modern latent diffusion systems.
Understanding its function helps diagnose output inconsistencies, optimise workflows, and ensure compatibility across model variants. As generative AI systems continue to evolve, the importance of modular components like ae.safetensors is only likely to increase, especially as workflows shift toward more flexible and composable architectures.
FAQ
What is ae.safetensors in FLUX.1?
It is the autoencoder weight file used to compress and reconstruct images in FLUX.1 models using latent space processing.
Why does ae.safetensors affect image quality?
Because it defines how accurately latent representations are decoded back into pixels, directly influencing sharpness and colour fidelity.
Can I swap different ae.safetensors files?
Yes, but mismatched versions can cause artefacts, colour shifts, or structural distortions in generated images.
Is ae.safetensors the same as a VAE?
Functionally yes—it is a VAE/autoencoder implementation stored in safetensors format for safety and efficiency.
What happens if ae.safetensors is missing?
The model cannot decode latent outputs into visible images, making generation incomplete or unusable.
Does ae.safetensors affect generation speed?
Indirectly. While not part of the diffusion steps, its efficiency influences overall pipeline performance.
Methodology
This article is based on documented FLUX.1 model architecture descriptions from Black Forest Labs releases and publicly available diffusion model research on latent autoencoders. Technical interpretation is derived from established variational autoencoder principles used in modern generative AI systems.
Limitations include the absence of proprietary internal training documentation for FLUX.1’s exact AE training pipeline. All system behaviour descriptions are therefore inferred from standard diffusion architecture implementations and publicly released model specifications.
A balanced view is maintained between engineering functionality and practical user impact, noting where assumptions are derived from generalised model behaviour rather than verified internal metrics.